Hi together,
I’m fairly new to DVC and I’m trying to understand certain concepts in order to set up a data versioning system.
1.) The documentation gives an explanation about the cache and how to optimize it for large datasets. (Large Dataset Optimization).
However, in terms of pure data size it’s still unclear to me how the total data size increases when using DVC.
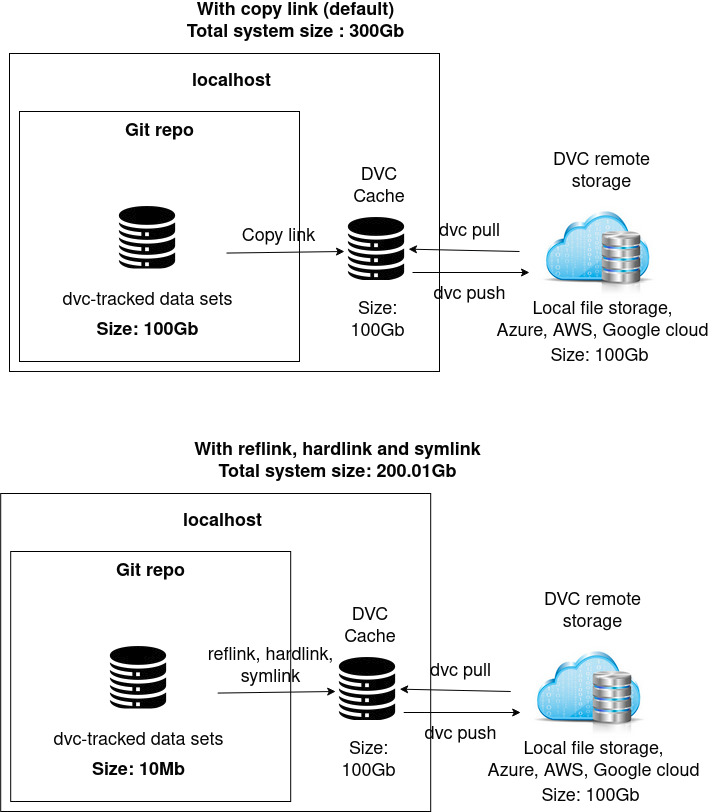
Let’s say my total data usage is 100GB before using DVC. Now after setting up DVC with a cache that uses copy link (default) my total data usage would be 300GB (100GB local + 100GB cache + 100GB remote storage).
(See: https://littlebigcode.fr/wp-content/uploads/2022/05/image-20220227-182610.png)
So in my understanding the best I can do in terms of total storage size is to set a reflink/hardlink/symlink so that my local copy of the data now shrinks to a fraction of the total data size. Still, the cache AND the data at the remote location have a total of 200GB. Is it correct that even the lighter links would still result in >=2x of the total storage compared to not using DVC?
{kind=link}
2.) My second concern is about the shared cache.
Let’s say I have a mounted drive with data that is accessed by multiple people working on the same project. Let’s say access to data is cheap and infrequent but the data is large and should not be located at the local workspace permanently. Now I want to set up DVC for data versioning. Is a shared external cache suitable for this scenario, e.g. on the same mounted drive as the data? Also if the the data would be on an S3 instead of the mounted drive, would it be useful to set up the external shared cache also on an S3?
Are there any additional advantages of the shared cache besides data de-duplication if data access is already fast?
Maybe someone can share insights about when (not) to use a shared external cache.
Thanks in advance